
Realtime word count using Hazelcast Jet with Clojure
Hazelcast Jet is a new kid on the block of real time big data computations. It allows to do both batch and real time analytics in the likes of Apache Spark and others.
In this example, we would like to simply counts frequencies of all the words of a text-file book. We will be using Frankenstein as the base book, so as the code itself does not look too scary.
The code sample is Clojure based, the jet wrapper comes from jet-into-jet and we will also use the wrapper for the Hazelcast in-memory grid, chazel.
As a heads up, we’ll be following the code flow below:
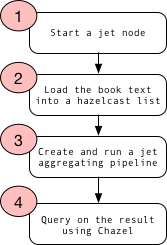
Right now we will start a REPL directly from a clone jet-into-jet git checkout and after starting a REPL, we are doing some Clojure namespace definition with the necessary imports and requires.
(ns pipes.pipe03
"Wordcount for pros. (о´∀`о)"
(:import
[com.hazelcast.jet.aggregate AggregateOperations]
[com.hazelcast.jet.function DistributedFunctions])
(:require
[chazel.core :refer :all]
[jet.core :as jet]))
First steps, is to start a new jet instance (or a node if you already have jet running somewhere). This is done rather simply with new-instance.
; start jet
(jet/new-instance)
You’ll see the work-of-art jet logo in the console output, telling you jet is up and running.
o o o o---o o---o o o---o o o---o o-o-o o o---o o-o-o
| | / \ / | | | / \ | | | | |
o---o o---o o o-o | o o---o o---o | | o-o |
| | | | / | | | | | | | \ | | |
o o o o o---o o---o o---o o---o o o o---o o o--o o---o o
With this jet instance running, we actually also started a Hazelcast In-Memory-Data-Grid node, and so we have access to all of the in-memory data structures.
We now read the book in text format, and inserts the lines of the book one by one in a hazelcast list, each element is a line of the book.
We insert all the lines in one go, so this uses a bit of memory but is actually quite fast, in the order of milliseconds.
; load book into hazelcast list
(def frankenstein
(hz-list "frankenstein"))
(with-open [rdr (clojure.java.io/reader "src/main/resources/frankenstein.txt")]
(.addAll frankenstein (into [] (line-seq rdr))))
; how many lines ?
(count frankenstein)
; 7653
Next we are on creating a jet pipeline for aggregation.
Functional-like functions for jet in standard java code are defined using lambdas, which we have to convert to standalone namespaces/classes in Clojure in order for the functions to be properly serializable accross the nodes of the jet cluster.
apply is the functional-looking method defined that we need to implement in order to use a function along the map step of the pipe flow.
In essence, the apply function here converts a whole sentence, from the input, to lowercase, and then emits words one word at a time to the next step in the pipeline. The splitted emits are done using traverseArray.
(ns pipes.fn.traverse
(:import [com.hazelcast.jet Traversers])
(:gen-class
:implements
[java.io.Serializable
com.hazelcast.jet.function.DistributedFunction]))
(defn -apply [this sentence]
(-> sentence
(.toLowerCase)
(.split "\\W+")
(Traversers/traverseArray)))
The pipeline below is done using the Clojure DSL coming with jet-into-jet. We define four steps:
- draw-from, where we read elements from the hazelcast list “frakenstein”, the list where the whole book content was loaded.
- flat-map, where we apply the function in parameter, traverse, to split up sentences into lower-cased words
- group-by, where we keep the whole word as the target for grouping, and increase the count by one for each word new instance, or simply said, count the word occurence.
- drain-to, where we store the result. This will be a map, made of words, and their respective frequency in the book.
(jet/pipeline [
[:draw-from (jet/source :list "frankenstein")]
[:flat-map (jet/new-fn (quote pipes.fn.traverse))]
[:group-by (DistributedFunctions/wholeItem) (AggregateOperations/counting) ]
[:drain-to (jet/sink :map "counts")]])
The above defines and runs the pipe at the same time on the existing jet instance or node and after a few milliseconds, the result is stored into the “counts” map in the hazelcast grid.
Now to see the result, we can use chazel’s DSL to query the content, a Hazelcast Map, with SQL-like queries.
To print the 10 words with the highest frequencies, you would sort the map entries based on the highest frequencies, using select and order-by.
(-> (hz-map "counts")
(select "*" :page-size 10 :order-by #(compare (val %2) (val %1)) :as :map)
:results
(clojure.pprint/pprint))
; {"" 1303,
; "of" 2760,
; "my" 1776,
; "that" 1033,
; "a" 1449,
; "and" 3046,
; "i" 2849,
; "to" 2174,
; "the" 4371,
; "in" 1186}
To print the 5 words with the lowest frequencies, you would sort the map entries the other way around.
(-> (hz-map "counts")
(select "*" :page-size 5 :order-by #(compare (val %1) (val %2)) :as :map)
:results
(clojure.pprint/pprint))
; {"skirted" 1,
; "skirting" 1,
; "accessed" 1,
; "indiscriminately" 1,
; "duvillard" 1}